
来源:https://github.com/SherlockLiao/pytorch-beginner/blob/master/01-Linear%20Regression/Linear_Regression.py
import torch
from torch import nn, optim
from torch.autograd import Variable
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
plt.plot(x_train, y_train, 'r.')
plt.show()
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
# Linear Regression Model
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression()
# 定义loss和优化函数
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-4)
# 开始训练
num_epochs = 1000
for epoch in range(num_epochs):
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out, target)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 20 == 0:
print('Epoch[{}/{}], loss: {:.6f}'
.format(epoch+1, num_epochs, loss.data[0]))
model.eval()
predict = model(Variable(x_train))
predict = predict.data.numpy()
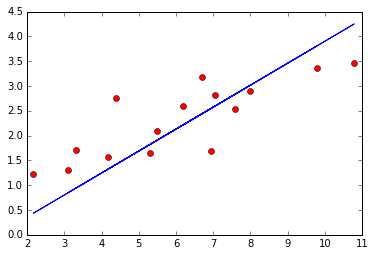
plt.plot(x_train.numpy(), y_train.numpy(), 'ro', label='Original data')
plt.plot(x_train.numpy(), predict, label='Fitting Line')
plt.show()
Epoch[20/1000], loss: 34.622749
Epoch[40/1000], loss: 24.584074
Epoch[60/1000], loss: 17.489223
Epoch[80/1000], loss: 12.474909
Epoch[100/1000], loss: 8.931002
Epoch[120/1000], loss: 6.426298
Epoch[140/1000], loss: 4.656044
Epoch[160/1000], loss: 3.404861
Epoch[180/1000], loss: 2.520526
Epoch[200/1000], loss: 1.895463
Epoch[220/1000], loss: 1.453635
Epoch[240/1000], loss: 1.141310
Epoch[260/1000], loss: 0.920511
Epoch[280/1000], loss: 0.764395
Epoch[300/1000], loss: 0.653995
Epoch[320/1000], loss: 0.575905
Epoch[340/1000], loss: 0.520649
Epoch[360/1000], loss: 0.481532
Epoch[380/1000], loss: 0.453820
Epoch[400/1000], loss: 0.434169
Epoch[420/1000], loss: 0.420215
Epoch[440/1000], loss: 0.410288
Epoch[460/1000], loss: 0.403206
Epoch[480/1000], loss: 0.398136
Epoch[500/1000], loss: 0.394487
Epoch[520/1000], loss: 0.391843
Epoch[540/1000], loss: 0.389910
Epoch[560/1000], loss: 0.388478
Epoch[580/1000], loss: 0.387401
Epoch[600/1000], loss: 0.386575
Epoch[620/1000], loss: 0.385926
Epoch[640/1000], loss: 0.385402
Epoch[660/1000], loss: 0.384968
Epoch[680/1000], loss: 0.384596
Epoch[700/1000], loss: 0.384268
Epoch[720/1000], loss: 0.383972
Epoch[740/1000], loss: 0.383698
Epoch[760/1000], loss: 0.383440
Epoch[780/1000], loss: 0.383193
Epoch[800/1000], loss: 0.382955
Epoch[820/1000], loss: 0.382722
Epoch[840/1000], loss: 0.382493
Epoch[860/1000], loss: 0.382267
Epoch[880/1000], loss: 0.382043
Epoch[900/1000], loss: 0.381821
Epoch[920/1000], loss: 0.381600
Epoch[940/1000], loss: 0.381380
Epoch[960/1000], loss: 0.381161
Epoch[980/1000], loss: 0.380942
Epoch[1000/1000], loss: 0.380724
# 保存模型
torch.save(model.state_dict(), './linear.pth')



Leave a Comment